This article explores using statistical methods to simulate a sales team. From the sales team simulation a set of `historical’ training data is created to fit model which can predict the value of any sales prospects which have not been closed. The predictions are provided as a band giving the upper and lower revenue estimate to a 95% confidence interval. This research acts as a proof of principle that such techniques are be able to be to provide useful information to sales managers.
1 Introduction
A friend of mine manages a sales team. He takes a very analytical approach to the sales process, but has often mentioned the lack of tools available for his projections. This surprised me, as the firm lives or dies based off the performance of its sales team. This article investigates modelling the sales process and the feasibility of predicting future income. The entire sales process is a messy system with lots of moving parts. To make the problem solvable it needs to be broken down into parts. This article focuses on valuing a set of sales prospects, or `pipeline’, at a given point in future based upon historical performance.
2 Terminology
This article is designed to be read by both data scientists and sales managers. There will be many people outside the overlap in the proverbial Venn diagram so I will go over some terminology first.
Throughout this paper the terms `sales prospect’ and `deal’ are used interchangeably to describe the process through which a salesperson first contacts a client and eventually sells something to them. If the salesperson sells the client something then the deal is considered to be closed successfully and failed otherwise.
In this article there are many references to statistical distributions with particular focus paid to Gaussian and Poisson distributions, which are shown in figure 1. As a rule of thumb, Gaussian distributions describe situations with continuous values around some average, e.g. a person’s height, and Poisson distributions describe something that occurs only a few times, e.g. the number of goals scored in a football match. For example, it is assumed that the value of a salesperson’s deal follows a Gaussian distribution with an average value and fixed spread (standard deviation). To model future deals a value is selected with the probability that follows a Gaussian distribution, i.e. values that are closer to the average are more likely than those which are far away. This is method is referred to in this article as applying a Gaussian smearing to an expected value.
3 Generating Historical Sales Data
A company’s sales history is confidential information and is not publicly available. As such, this research generates its own data to test ideas by modelling a sales team. The lack of real data will necessarily reduce the applicability of the results but will allow the concepts to be explored. The model has two sets of entities in it:
- salespersons which have a set of qualities corresponding with generating sales prospects and
- sales prospects which have features based on the generating salesperson but act independently.
3.1 Sales Prospects
The information about a sales prospect that companies record vary between businesses. This is because the database of historical sales can be used in many ways, with each needing a different set of data. However, a common use case in all businesses is for review by a sales manager. As such, each sales prospect needs to keep track of the following features:
- The date when the sales prospect is first input into the system.
- The date when the sales prospect concludes.
- The initial estimate of the sale prospect’s value.
- The final value of the sales prospect.
- The discount applied on the deal.
These top-level data are used by management to evaluate sales performance. To model a sale, extra pieces of information are required to determine the behaviour of the deal. There are three key modelling variables, the expected deal length, chance of it failing and the difference between the opening price and the closing price.
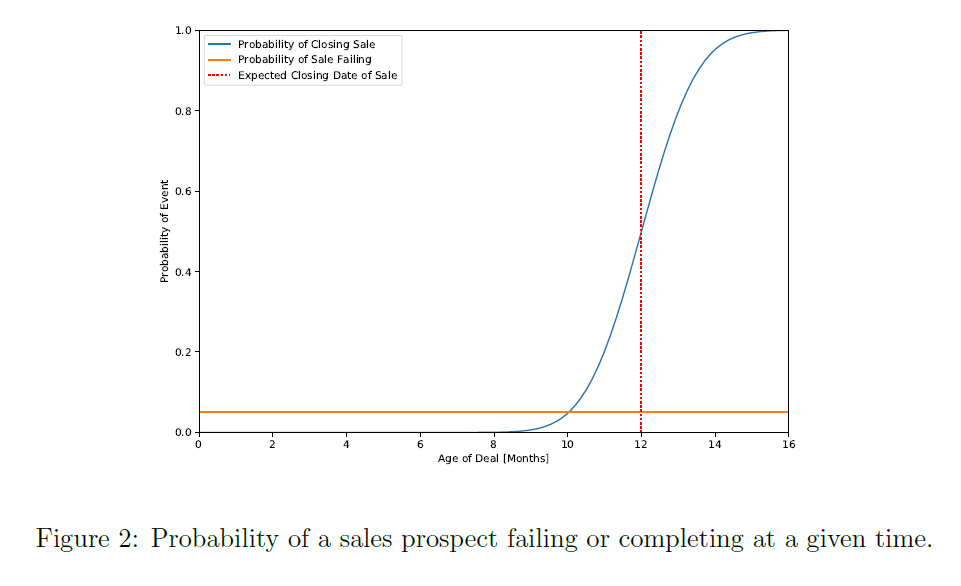
Figure 2 shows how the failure rate and closing time is modelled, where the probabilities of the sale either closing or failing at a given time are shown. The failure rate for a given time is constant, e.g. a sales prospect has the same chance of failing between any two time intervals as any other. The probability of closing a sale is modelled as an expected close date with a Gaussian smearing, where the chance of completion tends to one as the deal moves past its expected close date. If a sale prospect successfully closes, then the final value is decided by the opening value multiplied some Gaussian smeared discount factor. This final smearing accounts for two affects, the change in deal value throughout its lifetime and discount applied to make the sale. These modelling variables are all provided by the salesperson who creates the sales prospect.
3.2 Salespeople
A salesperson is responsible for generating new sales prospects and setting their characteristics based on the abilities of the salesperson. In this model, a salesperson has the following characteristics:
- average deal length,
- deal length uncertainty,
- deal failure rate,
- average deal value,
- deal value uncertainty,
- average discount,
- discount uncertainty and
- deals generated per month.
Each month a salesperson generates a number of new sales prospects based upon a Poisson distribution of the expected number of deals. Each deal has an opening value based on the average deal value and is smeared by the deal value uncertainty. The other features of the salesperson are passed to the sales prospect and modelled by the deal.
3.3 Running the Model
A Monte-Carlo simulation is used to generate the data. Time is progressed forward month by month and at each time step every salesperson is tested to see if they generate any new deals. These deals are added to the pipeline. Old sale prospects in the pipeline are then progressed, each one is tested to see if it fails that month or if it completes. Simulating a few years of data can be done quickly to provide a baseline for the later modelling.
4 Modelling Historical Behaviour
There are some obvious defects with simulating historical sales data and then training a predictive model on it. The main issue is that the `natural/intuitive’ assumptions of modelling that one would go into the fitting the data also went into creating the data. This likely leads to better performance in the predictor than would be seen in a model based off real sales history. To minimize this effect, we will use simple techniques that do not make many assumptions.
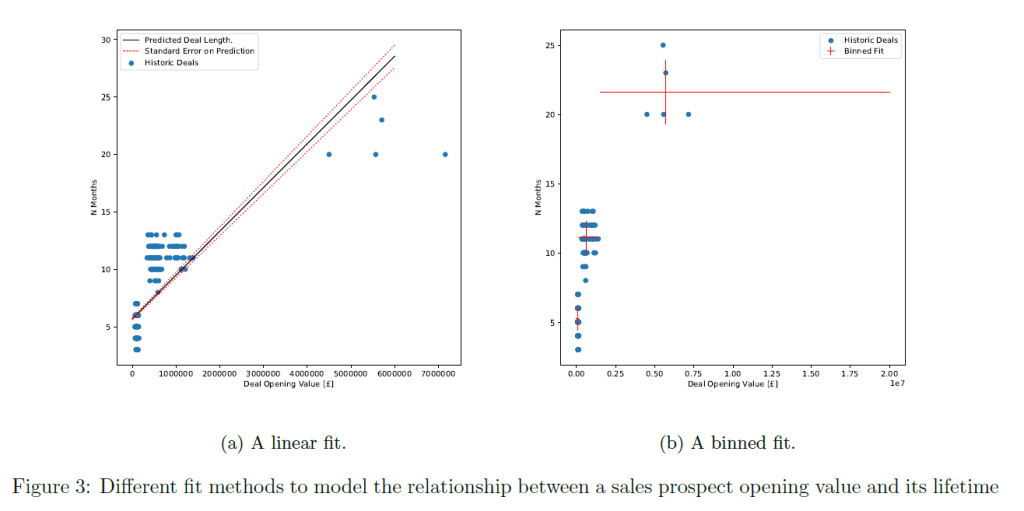
In predicting the future revenue from a sales pipeline, we need to know when a deal will close to realize the revenue. Figure 3 shows a sales prospect opening value versus its age upon completion and two methods to fit this data. A clear relationship between a sales prospect opening value and its lifetime can be seen. A linear model and binned fit both produce reasonable results for predicting an expected lifetime value. However, it can be seen the deals with a larger opening value are predicted to have a systematically longer lifetime than in the data. The linear model also under-predicts the variance. With real sales data it would be worth spending more time improving upon these models. However, as the training dataset is artificial the binned fit is good enough for the purposes of this research.
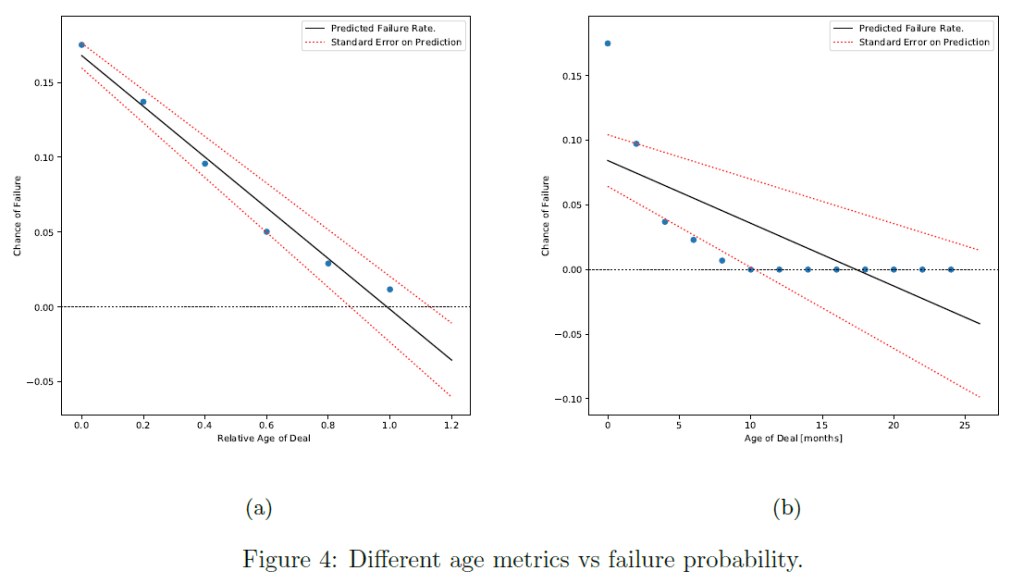
The next part of predicting a sales prospect eventual revenue is working out the chance it will fail before completion. The working theory is that deals have a similar chance of failing regardless of opening value. This is justified by assuming that salespeople who take on larger more complex deals are also better at completing them. Thus, the additional difficulty is balanced by the increased skill. Under this assumption, the primary determinant is the deals age. The older a deal the more hurdles it has overcome and the less it has in front of it. To determine the failure chance of a sales prospect the historical data is queried to check of those jobs which are of age x or older (i.e. were at age x at some point), what percentage failed. Figure 4 show the results of this query using the age of deals in months and the relative age of a deal compared to its age predicted by the binned lifetime fit model. A linear regression is fitted to both age metrics to generalize the results. The first thing to notice is that the linear model predicts negative failure chance probabilities. This is expected as the model has no concept of a maximum age and any negative relation will pass through zero at some point. It is corrected by enforcing a lower bound on the model prediction of 0. Looking at the failure rate verses the raw age raises two issues. The first is that the failure rate is clearly non-linear and the second is that the historical data shows a failure rate of 0 after 10 months. This is contrasted with a model based on relative age where a linear model describes the behaviour well and it gives a positive failure probability up until it is expected to complete. Due to this better behaviour, the relative age will be used a predictor of failure.
The final part of the modelling is the discount applied to the opening value when a deal closes. This is more straight forward than the other as it can be treated as a single number applied to all open deals. This is done by taking the average percentage discount applied to completed deals. The uncertainty on this value can be calculated by assuming it is normally distributed and taking its standard deviation.
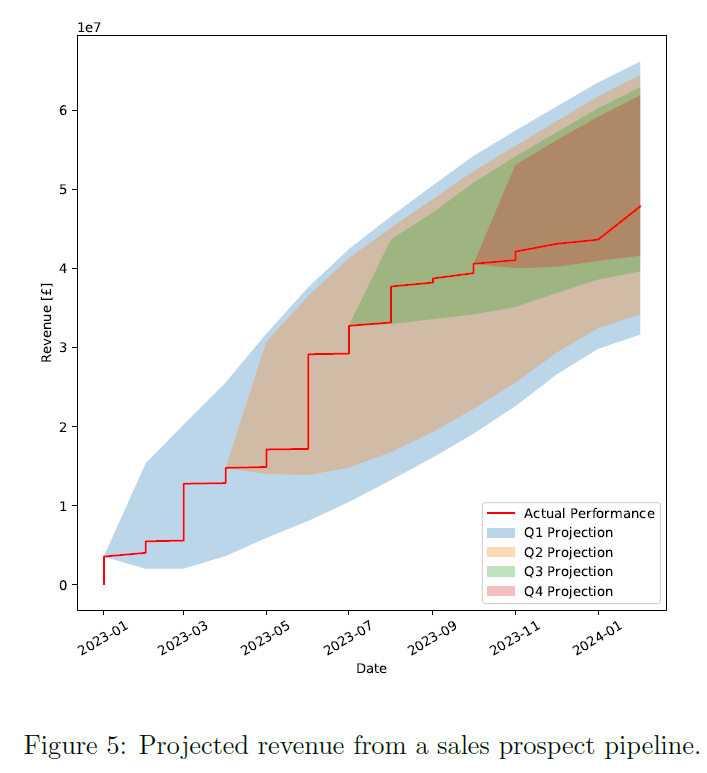
5 Predicting the Future Value of A Pipeline
There is now enough information to evaluate the future value of a sales pipeline. For any given point in time a deal can be corrected by its expectation of completing, its chance of failing and the expected discount. With the assumptions stated in section 3 the uncertainty around this expected value can also be calculated. By applying the same process that was used to generate the historical data to the existing pipeline, it can be progressed through time to allow projections to be made each quarter and the `true’ revenue to be shown as well. Figure 5 shows a revenue projection with a 95% confidence of interval where the confidence interval implies that `real’ outcome will only have a 1 in 20 chance of going outside the bands. Although, the accuracy of the confidence intervals is only as good as the models used to derive it – so if there is a new situation not seen in the historical data then all bets are off.
A benefit of modelling the expected value of each deal at any point of time is it allows a sales manager to identify which sales and salespeople are most important for a given quarter to give them special attention. It also helps identify which salespeople are falling short of their targets to provide help.
6 Conclusion
The models used here are relatively simple and fall far short of those that would be needed to be useful in a real sales environment. There is bound to be all sorts of complex human behaviours that would need to be accounted for. However, as a proof of principle this research shows the practical application of modelling the sales life cycle. One area this research falls short on is modelling individual salespeople based on the historic data to produce predictions of revenue based on new sales prospects created throughout the year. With this, a sales manager could more accurately forecast their income and identify areas that need their attention. A more robust model could also help inform strategic decisions as their effect could be estimated and compared to their cost of implementation or opportunity cost.
